이 바이트 배열 인터페이스는 오직 컬럼 표현식으로만 다룰 수 있으므로 사용자에게 절대 노출되지 않음.
5.3.1 로우 생성하기
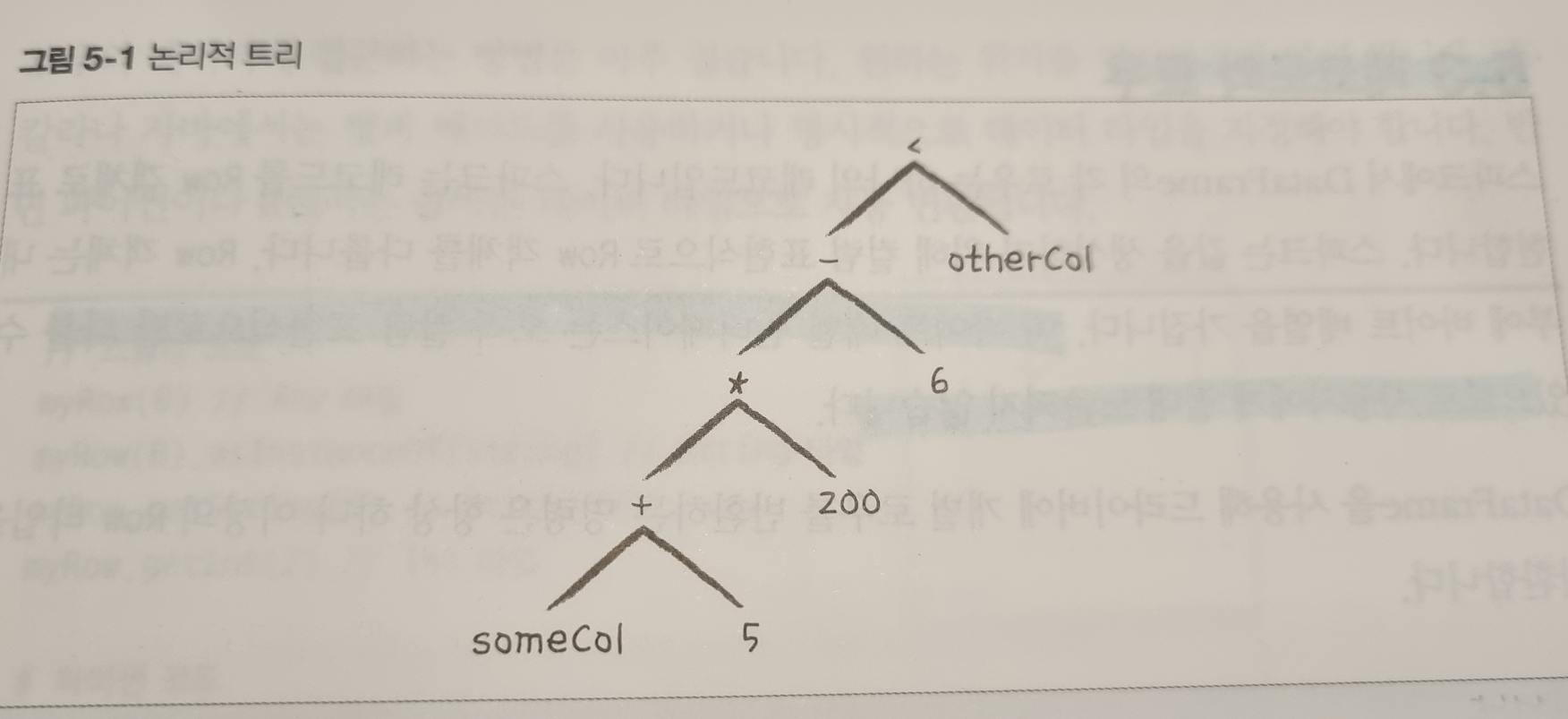
Row객체는 스키마 정보를 가지고 있지 않음. DF 만 유일하게 스키마를 가지고 있음.
Row 함수를 통해 직접 Row를 생성하는 것이 가능함.
1
2
3
4
5
6
7
8
frompyspark.sqlimportRowmyRow=Row("Hello",None,1,False)# index를 통해 직접 접근이 가능함.
myRow[0]myRow[2]
5.4 DataFrame의 트랜스포메이션
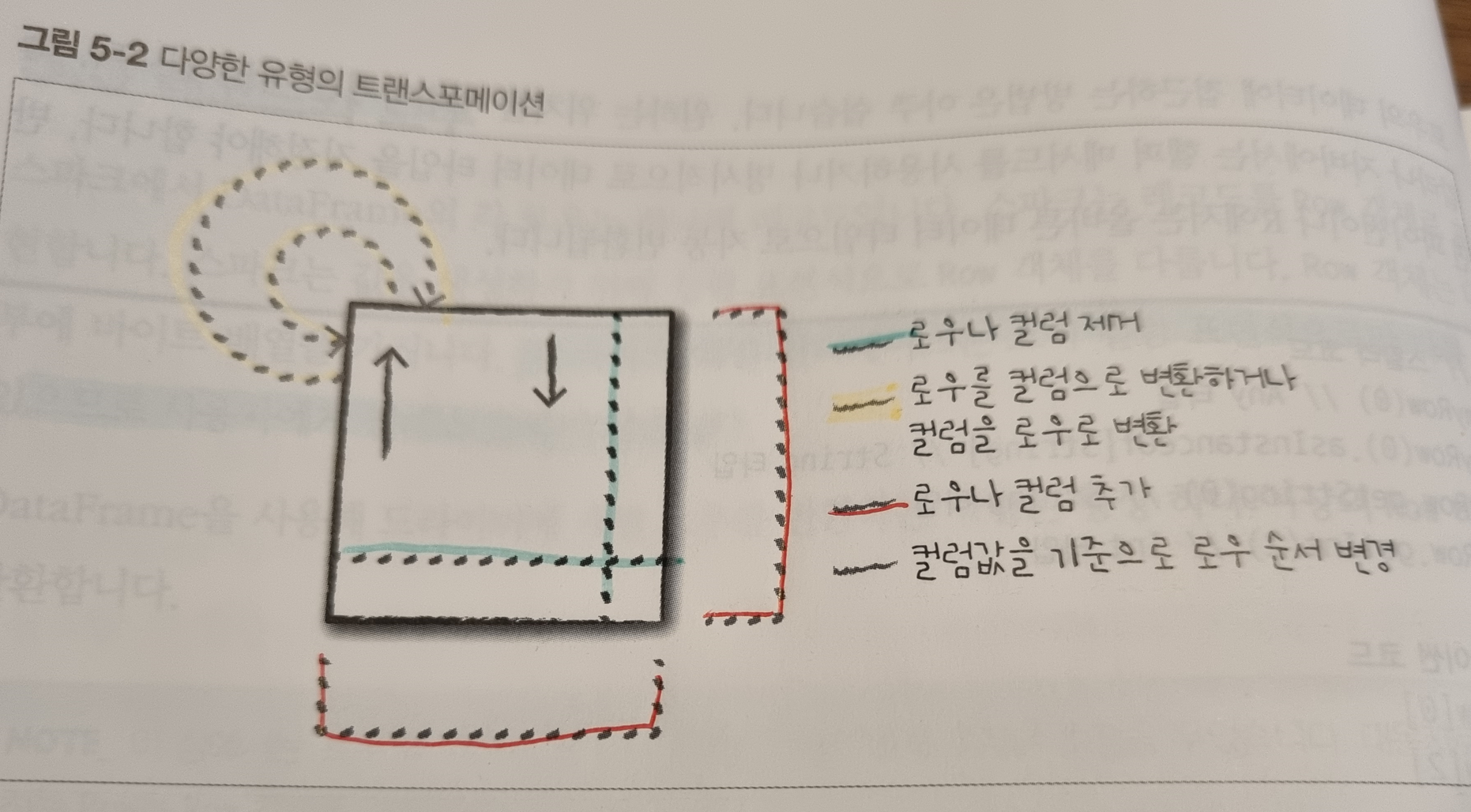
해당 장에서는 몇가지 DataFrame을 다루는 방법에 대해 소개.
로우나 컬럼 추가
로우나 컬럼 제거
로우를 컬럼으로 변환하거나, 그 반대로 변환
컬럼값을 기준으로 로우 순서 변경
가장 일반적인 트랜스포메이션은 모든 로우의 특정 컬럽값을 변경하고, 그 결과를 반환하는 것
df.select( col(“count”) + 5 ) 이런것을 말하는 것 같음
5.4.1 DataFrame 생성하기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 데이터 소스를 통해 DF 생성
df=spark.read.format("json").load("/data/flight-data/json/2015-summary.json")df.createOrReplaceTempView("dfTable")# 사용자가 직접 Schema를 정의해서 DF 생성
frompyspark.sqlimportRowfrompyspark.sql.typesimportStructField,StructType,StringType,LongTypemyManualSchema=StructType([StructField("some",StringType(),True),StructField("col",StringType(),True),StructField("names",LongType(),False)])myRow=Row("Hello",None,1)myDf=spark.createDataFrame([myRow],myManualSchema)myDf.show()
5.4.2 select and selectExpr
select 구문
일반적으로 아래의 코드와 같이 사용된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# COMMAND ----------
# select를 통해 column을 명시하는 것으로 데이터 호출이 가능
df.select("DEST_COUNTRY_NAME").show(2)# COMMAND ----------
# 여러개를 호출하는 것도 가능하다
df.select("DEST_COUNTRY_NAME","ORIGIN_COUNTRY_NAME").show(2)# COMMAND ----------
# expr, col, column 표현식으로 통해 데이터를 호출하는 것도 가능하다
frompyspark.sql.functionsimportexpr,col,columndf.select(expr("DEST_COUNTRY_NAME"),col("DEST_COUNTRY_NAME"),column("DEST_COUNTRY_NAME"))\
.show(2)
# COMMAND ----------
df.select(expr("DEST_COUNTRY_NAME AS destination")).show(2)# COMMAND ----------
df.select(expr("DEST_COUNTRY_NAME as destination").alias("DEST_COUNTRY_NAME"))\
.show(2
selectExpr
select를 쓰다보면 expr를 자주쓰는 경우가 많아서 아예 selectExpr이라는 것을 제공해줌.
새로운 DF를 생성할때 복잡한 표현식을 간단하게 만들 수 있어 자주 사용된다고 함.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# COMMAND ----------
df.selectExpr("DEST_COUNTRY_NAME as newColumnName","DEST_COUNTRY_NAME").show(2)# COMMAND ----------
# 표현식을 통해서 새로운 Column을 쉽게 만들 수 있다!
df.selectExpr("*",# all original columns
"(DEST_COUNTRY_NAME = ORIGIN_COUNTRY_NAME) as withinCountry")\
.show(2)# COMMAND ----------
# 집계 함수도 간단하게 뽑아볼 수 있음.
df.selectExpr("avg(count)","count(distinct(DEST_COUNTRY_NAME))").show(2)
5.4.3 스파크 데이터 타입으로 변환하기
때로는 새로운 컬럼이 아닌 명시적인 값을 스파크에 전달해야 될 때가 있음.
이 때, 리터럴이 사용되는데 프로그래밍 언어의 리터럴 값을 스파크가 이해할 수 있는 값으로 변환.
withColumn 같은것은 상관이 없고, selectExpr은 내부 구현상으로 저렇게 구분이 되어야 하는 듯.
selectExpr은 아마도 SQL Query로 변환하는 작업 같은게 있는거 같음.
1
2
3
4
5
6
7
8
9
10
11
12
# COMMAND ----------
dfWithLongColName=df.withColumn("This Long Column-Name",expr("ORIGIN_COUNTRY_NAME"))# COMMAND ----------
dfWithLongColName.selectExpr("`This Long Column-Name`","`This Long Column-Name` as `new col`")\
.show(2)
collectDF=df.limit(10)collectDF.take(5)# take works with an Integer count
collectDF.show()# this prints it out nicely
collectDF.show(5,False)# 컬럼을 축약하지 않고 그대로 다 보여줌. truncate = False
collectDF.collect()# DF의 모든 데이터를 수집.
댓글남기기