[파이썬 코딩의 기술 : Effective PYTHON 2ND 요약 및 코드 정리] CHAPTER 7. 동시성과 병렬성
52. 자식 프로세스를 관리하기 위해 subprocess를 사용하라
subprocess는 python에서 child process를 관리하기 위해 사용하는 built-in 모듈.
책에서는 subprocess.Popen을 사용해 관리할 것을 권유하고 있으며 기본적인 사용방법은 https://docs.python.org/ko/3/library/subprocess.html 링크에 있음.
한 가지 유의할 점은 communicate를 사용하기 전 buffer를 close하면 바로 프로그램이 실행이 된다는 점을 주의. stdin은 왠만하면 직접 건드리지 않는 것이 좋을듯.
- Code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
import subprocess
import os
def run_encrpy(data):
# 여기서 env는 환경변수를 뜻함.
env = os.environ.copy()
env['password'] = 'zf7ShyBhgZ0raQDdE/FiZpm/m/8f9X+M1'
proc = subprocess.Popen(
['openssl', 'enc', '-des3', '-pass', 'env:password'],
env=env,
stdin=subprocess.PIPE,
stdout=subprocess.PIPE)
proc.stdin.write(data)
proc.stdin.flush()
return proc
def run_hash(input_stdin):
return subprocess.Popen(
['openssl', 'dgst', '-whirlpool', '-binary'],
stdin=input_stdin,
stdout=subprocess.PIPE)
encrpyt_procs = []
hash_procs = []
for _ in range(3):
data = os.urandom(100)
encrpyt_proc = run_encrpy(data)
encrpyt_procs.append(encrpyt_proc)
hash_proc = run_hash(encrpyt_proc.stdout)
hash_procs.append(hash_proc)
encrpyt_proc.stdout.close()
encrpyt_proc.stdout = None
for proc in encrpyt_procs:
proc.communicate()
assert proc.returncode == 0
for proc in hash_procs :
# communicate는 stdout, stderr를 반환한다.
# 이는 앞서 stdout을 subprocess.PIPE로 설정해서 그런 것임.
out, _ = proc.communicate()
print(out[-10:])
assert proc.returncode == 0
- Result
1
2
3
4
5
6
7
8
9
*** WARNING : deprecated key derivation used.
Using -iter or -pbkdf2 would be better.
*** WARNING : deprecated key derivation used.
Using -iter or -pbkdf2 would be better.
*** WARNING : deprecated key derivation used.
Using -iter or -pbkdf2 would be better.
b'b\x05\xa4\x8eT1\x19\x18\x14\xd0'
b'\xb9\xa4\xa7*\x8e\xee\x10\x80\\\xbe'
b'\xd0\xe9\xa1?\xc3[\xf4d\xbe\xda'
53. 블로킹 I/O의 경우 스레드를 사용하고 병렬성을 피하라
Python은 코드 실행시 GIL(Global interpreter Lock)을 사용하기 때문에,
Thread 사용시 일반적인 경우에 다른 언어들이 취할 수 있는 이점을 취할 수 없다.
단 한가지 이점이 생길 수 있는 경우가 있는데, 그것은 Blocking I/O가 진행될때이다.
이 때는 CPU Bound Task가 아니기 때문에 switching이 많이 발생하지 않아 문제가 되지 않는다.
coroutine, asyncio 같은 다른 대안들도 있으나 Threading이 직관적이기 때문에 Blocking I/O 사용시에만 Thread를 사용하자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
def factorize(number):
for i in range(1, number + 1):
if number % i == 0:
yield i
import time
numbers=[2139079, 1214759, 1516637, 1852285]
start = time.time()
for number in numbers:
list(factorize(number))
end = time.time()
delta = end - start
print(f'{delta=:.3f}')
from threading import Thread
class FactorizeThread(Thread):
def __init__(self, number):
super().__init__()
self.number = number
def run(self):
self.factors = list(factorize(self.number))
start = time.time()
threads = []
for number in numbers:
thread = FactorizeThread(number)
thread.start()
threads.append(thread)
for thread in threads:
thread.join()
end = time.time()
delta = end - start
print(f'{delta=:.3f}')
54. 스레드에서 데이터 경합을 피하기 위해 Lock을 사용하라
앞서 언급된 GIL로 인해서 보통의 경우에도 Thread safe가 보장된다고 생각한다면 그렇지 않다.
물론 어느정도 보장이 되는 컨테이너도 있을 수 있지만 그렇지 않다.
이것은 += 연산 도중 내부 동작은 여러가지로 나뉘게 되는데 이때 thread별 ProgramCounter는 thread 시작시 트랜잭션 처리되지 않기 때문에 switching 발생시에 mutex 보장을 해주지 않기 떄문이다. GIL은 refer counter 등을 보장해줄 뿐 실제 이런 연산에 대해서는 thread safe 하게 동작되지 않는다.
그래서 Lock을 사용해서 mutex를 걸어주면 data 영역에 대해서 thread safe를 보장해준다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
from threading import Thread
class Counter:
def __init__(self):
self.count = 0
def increment(self, offset):
self.count += offset
def worker(sensor_index, how_many, counter):
for _ in range(how_many):
counter.increment(1)
how_many = 10**6
counter = Counter()
threads = []
for i in range(5):
thread = Thread(target=worker,
args=(i, how_many, counter))
threads.append(thread)
thread.start()
for thread in threads:
thread.join()
expected = how_many * 5
found = counter.count
print(f'{expected=}, {found=}')
1
expected=5000000, found=2988814
1
2
3
4
5
6
7
8
9
10
from threading import Thread, Lock
class Counter:
def __init__(self):
self.lock = Lock()
self.count = 0
def increment(self, offset):
with self.lock:
self.count += offset
1
expected=5000000, found=5000000
55. Queue를 사용해 스레드 사이의 작업을 조율하라
- thread 작업을 통제하기 위해 Queue 모듈을 사용하라는 내용.
- Queue 모듈 사용시에 아래의 이점들을 얻을 수 있음.
- busy-wating (반복문으로 종료 체크) 방지
- Worker에서 run을 무한히 반복하지 않아도 됨.
- Queue에 진행이 막힐 때, 크기가 커져서 메모리를 많이 사용하는 경우.
설명이 조금 과한거 같은데 번역도 엉망인거 같아서 일단 pass.
56. 언제 동시성이 필요할지 인식하는 방법을 알아두라
콘웨이의 생명 게임이라는 것을 예시로 보여준다. 5x5의 cell이 있고, 각 셀의 상태는 alive, empty로 나타낸다.
각 셀마다 근접한 셀의 상태가 alive인지 empty인지에 따라 cell을 empty로 바꿀것인지 alive로 바꿀 것인지 결정하는 게임이다.
동시성을 조율하는 가장 일반적인 방법으로 Fan-in, Fan-out이 있다.
- fan-in : 전체를 조율하는 프로세스안에서 다음 단계로 진행하기 전에 동시 작업 단위의 작업이 모두 끝날때까지 기다리는 과정을 팬인(Fan-in)이라고 한다.
- fan-out : 각 작업 단위에 대해 동시 실행되는 여러 실행 흐름을 만들어내는 과정을 팬아웃(fan-out)이라고 한다.
글로만 보면 이해가 잘 안되는데 그림을 그려보면 이해가 쉽다. 이 책은 번역이 어색해서 나의 생각을 다시한번 정리하게 해줘서 참 좋은 것 같다.
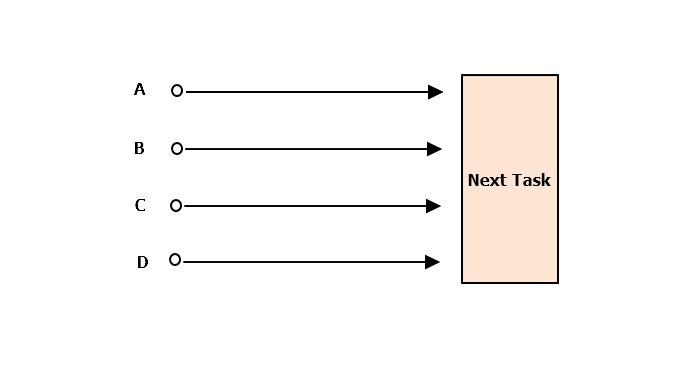
A,B,C,D단계는 Next Task로 가기전 실행이 된다. 이러한 실행의 흐름을 Fan-out 이라고 한다.
Next Task는 일을 진행하기 전 A,B,C,D단계를 수행해야 한다. 다음 단계로 가기 전에 진행되어야 하고 이를 기다리는 것을 Fan-in 이라고 한다.
57. 요구에 따라 팬아웃을 진행하려면 새로운 스레드를 생성하지 말라
새로운 thread를 생성해서 작업을 팬아웃(다음 단계로 가기 위해 Thread.start 수행)을 하면 돌아는 가지만 단점들이 많이 존재한다.
- Thread Safe하게 코드를 작성하려면 Lock을 사용해야하며 이는 코드의 가독성을 해친다. 그리고 유지보수도 어려워진다.
- 스레드는 하나당 메모리 8MB나 필요하다. 예제에서 나오는 게임의 셀이 10000개가 된다면 셀수없을 정도로 커지게 된다.
- 스레드는 시작하는 비용이 비싸다. context switching에 비용이 들기 때문에 성능에 부정적인 영향을 미친다.
이러한 문제 때문에 Queue나 ThreadPoolExecutor를 통해 구현하도록 지원을 해준다.
58. 동시성과 Queue를 사용하기 위해 코드를 어떻게 리팩터링해야 하는지 이해하라
앞선 57번 항목에서의 문제 때문에 Queue를 사용해 코드를 리팩터링 할 것을 권장한다.
아래 예제 코드를 보면 Queue를 사용해서 개선을 한 것을 볼 수 있는데, 복잡도가 어마어마하다.
https://github.com/gilbutITbook/080235/blob/master/Chapter7/Better%20way58_3.py
Thread 보다는 낫다고 하는데 개인적으로는 후자가 더 알아보기 힘든 것 같다.
확장성이 좋아지긴 하지만 기존 코드를 리팩터링 하려면 상당히 많은 작업이 필요하고, 특히 다단계로 이뤄진 파이프라인이 필요하면 작업량이 늘어난다.
다음장은 이러한 단점이 모두 보안된 concurrent.futures 라는 모듈에 대해서 살펴본다.
59. 동시성을 위해 스레드가 필요한 경우에는 ThreadpoolExecutor를 사용하라
Python에서는 위와 같은 단점들을 보완한 concurrent.future 모듈의 ThreadpoolExecutor 라는 클래스가 존재한다.
해당 클래스는 사용하기도 쉬울 뿐더러 위에서 나온 문제점들을 모두 보완한다.
- Executor 개수 제한 => max_worker 인자 사용
- Error 처리 => result() 함수로 결과를 받아올 수 있음.
이를 통해 처리한 소스는 다음과 같다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
from concurrent.futures import ThreadPoolExecutor
def simulate_pool(pool, grid):
next_grid = LockingGrid(grid.height, grid.width)
futures = []
for y in range(grid.height):
for x in range(grid.width):
args = (y, x, grid.get, next_grid.set)
future = pool.submit(step_cell, *args) # 팬아웃
futures.append(future)
for future in futures:
future.result() # 팬인
return next_grid
grid = Grid(5, 9)
grid.set(0, 3, ALIVE)
grid.set(1, 4, ALIVE)
grid.set(2, 2, ALIVE)
grid.set(2, 3, ALIVE)
grid.set(2, 4, ALIVE)
columns = ColumnPrinter()
with ThreadPoolExecutor(max_workers=10) as pool:
for i in range(5):
columns.append(str(grid))
grid = simulate_pool(pool, grid)
print(columns)
좀 더 자세한 내용에 관해서 알아보고 싶다면 아래 링크를 참조하자.
https://docs.python.org/ko/3.7/library/concurrent.futures.html#threadpoolexecutor
하지만 이 방법은 결국 제한된 수의 I/O 병렬성만 제공된다는 문제점이 남아있다.
10,000개 이상의 셀을 동시에 처리하고 싶어도 저 방법으로는 한계가 있다.
이를 해결하기 위한 다음 방법이 coroutine을 사용하는 방식이다.
60. I/O를 할 때는 코루틴을 사용해 동시성을 높여라
앞선 상황들보다 상황에 따라 더 좋은 성능을 내기 위해 코루틴을 사용할 것을 권장한다.
코루틴이나 asyncio에 관한 설명은 아래의 링크에서 살펴보자.
Corotine 설명 : http://www.dabeaz.com/coroutines/Coroutines.pdf
async : https://docs.python.org/ko/3/library/asyncio-task.html#running-an-asyncio-program
코루틴은 스레드를 사용하는 대신 Event loop 알고리즘을 사용해 마치 async 하게 동작하는 것처럼 프로그램을 실행시킬 수 있다.
스레드도 결코 만만한 비용을 사용하는 방식이 아니고 GIL로 인해 만족스러운 결과를 얻을 수 없을수도 있기에 async 개념이 python에도 존재한다.
코루틴 object를 만들려면 함수 앞에 async를 붙이면 된다.
그리고 비동기로 동작시킬 구문에는 await를 통해 결과를 대기하도록 만들면 해당 코드는 async하게 실행되는 알고리즘이 된다.
example : https://github.com/gilbutITbook/080235/blob/master/Chapter7/Better%20way60_3.py
61 ~ 63 pass
- 해당 내용은 아직 때가 아닌 것 같아 우선은 패스.
- asyncio에 대해서 좀 더 알아본 후에 살펴보자.
댓글남기기