[DataBase][NoSQL] 분산 KVS, 와이드 컬럼 스토어, 도큐먼트 스토어, 검색엔진에 대해서 알아보자 - 05. Performance 테스트
앞선 글까지 NoSQL의 4가지 종류(분산 KVS, WCS, Document Store, Search Engine)에
대해서 살펴보았다. 각 문서에서는 RDBMS와 비교했을시 NoSQL의 성능이 더 우수하다고
되어있지만 글로만 봐서는 체감이 되질 않는다.
그래서 이제는 실제로 얼만큼 성능의 차이가 나는지 체크 해보고자 한다.
이번 POST에서는 RDB(SQLITE) + NoSQL(분산 KVS, WCS, Document Store, Search Engine)간에 성능 테스트를 주제로 글을 작성해 보고자 한다.
Document Store의 경우에는 schemaless한 데이터들을 유연하게 적재할 수 있다는게 장점이기 때문에 성능 비교와는 거리가 먼 것 같아서 제외하도록 한다.
Performance 측정은 RDBMS에서도 가능하고 NoSQL에서도 가능한 목록들에 대해서 한번 체크를 해보려고 한다.
떠오르는 것들은 다음과 같다.
| index | RDBMS | NoSQL | What? |
|---|---|---|---|
| 1 | SQLITE-Index | KVS(DynamoDB, Cassandra) | Read/Write 속도 비교 |
| 2 | SQLITE-FTS | SearchEngine(ElasticSearch) | 검색 속도 비교 |
하나씩 차례대로 확인해보자.
1. RDBMS vs Key-Value Store 성능 비교
첫번째로 Key-Value Store와 RDBMS 사이에 어떠한 차이가 있는지에 대해서 비교를 해보자.
Key-Value Store의 장점은 Key별로 빠르게 데이터를 Read 하거나 Write를 할 수 있다는 점이다.
예를 들면 유저정보와 같이 Key를 통해서 데이터를 빠르게 주고받아야 할때 강점을 발휘한다.
과연 얼마나 차이가 날까? 한번 Test 해보자.
RDBMS는 SQLITE, Key-Value Store는 Apache Cassandra를 사용해 Test를 진행한다.
( 앞서 소개한 KVS인 DynamoDB는 요금 걱정때문에 우선은 제외.. )
유저 정보에 관한 Schema는 아래와 같이 정의해보았다.
유저 정보(client_info) Schema
| Column | Column(eng) | Description | Type | 범위 |
|---|---|---|---|---|
| 고객 id | user_id | 고객의 id | text | uuid_4 |
| 고객 pw | user_pw | 고객의 pw | text | 12자리 알파벳 + 숫자의 조합 |
| 고객 성명 | user_name | 고객의 이름 | text | - |
| 회원/비회원 | is_member | 고객이 회원인지 비회원인지? | boolean | 0 = 비회원, 1 = 회원 |
| 성별 | sex | 고객의 성별 | boolean | 0 = 여성, 1 = 남성 |
| 나이 | age | 고객의 나이 | int | 12~70 |
| 직업 | job | 고객의 직업에 대한 정보 | text | - |
| 주소 | home_address | 배송이 이뤄져야할 위치에 대한 정보 | text | - |
Test 1. 유저 정보 Read / Write
실시간 웹 서비스에서 유저의 정보를 빠르게 저장하고 가져오고 싶은 상황이 있다고 가정하자.
첫번째로 테스트할 내용은 실제 Write 속도가 얼마나 차이가 있을지에 대한 차이다.
아래의 테스트 환경으로 진행을 해보자.
Environments
- PC 사양
- CPU - AMD Ryzen 5 3500X 6-Core Processor(3.60 GHz)
- RAM - 16GB
- OS - Window 10 Home
- DB Engine : SQLITE3( Local ), Cassandra( Local, 1 Server )
- 최대 1000만명의 유저가 있다고 가정하고 Read/Write Test 진행.
- Key = 고객 id(user_id)
Test 1-1. Write Test
개수별로 차이가 있을 수 있어 이를 고려하여 100만, 500만, 1000만 rows를 대상으로 테스트해보았다.
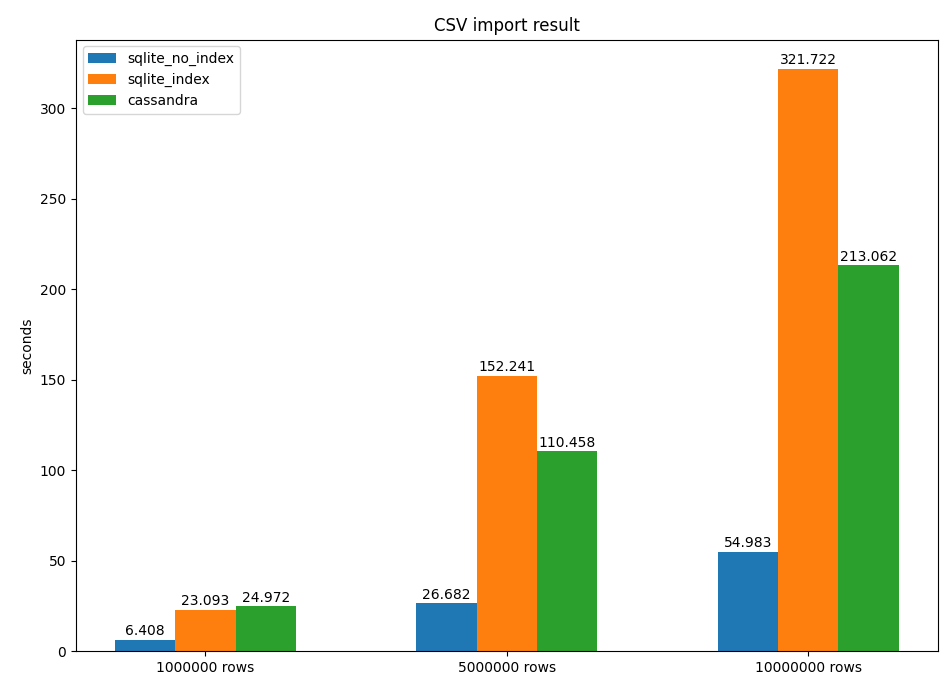
100만 rows를 write 할때는 속도가 크게 차이가 나지 않지만,
1000만 rows에서는 SQLITE가 무려 1.5배나 느린 것으로 확인되었다.
https://www.sqlite.org/speed.html에 따르면 sqlite는 다른 대표적인 RDBMS인 MySQL, PostgreSQL와 비교했을때 속도가 빠른 편이다. (꽤 오래 된 자료이기 때문에 현재는 다를 수 있음.)
이를 인용하면 일반 RDBMS보다는 cassandra에 Write를 하는 것이 더 빠르다고 볼 수 있을 것 같다.
아래 표를 보면 sqlite(no-index)의 경우가 가장빠르지만 실제 운영 환경에서는 read 속도를 위해 index를 생성할 것이므로 무시해도 될 것 같다.
Test 1-2. Read Test
다음은 Read Test를 진행해보았다.
| Case | 소요시간(sec) | image |
|---|---|---|
| SQLITE3 Read 1 record(No Index) | 1760 ms |  |
| SQLITE3 Read 1 record(Index) | 1~4 ms | 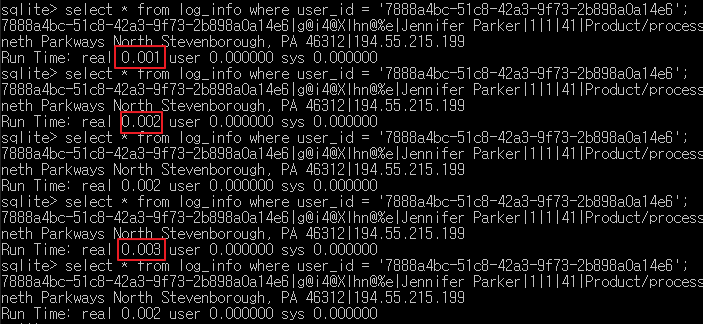 |
| CASSANDRA Read 1 record | 3 ms | 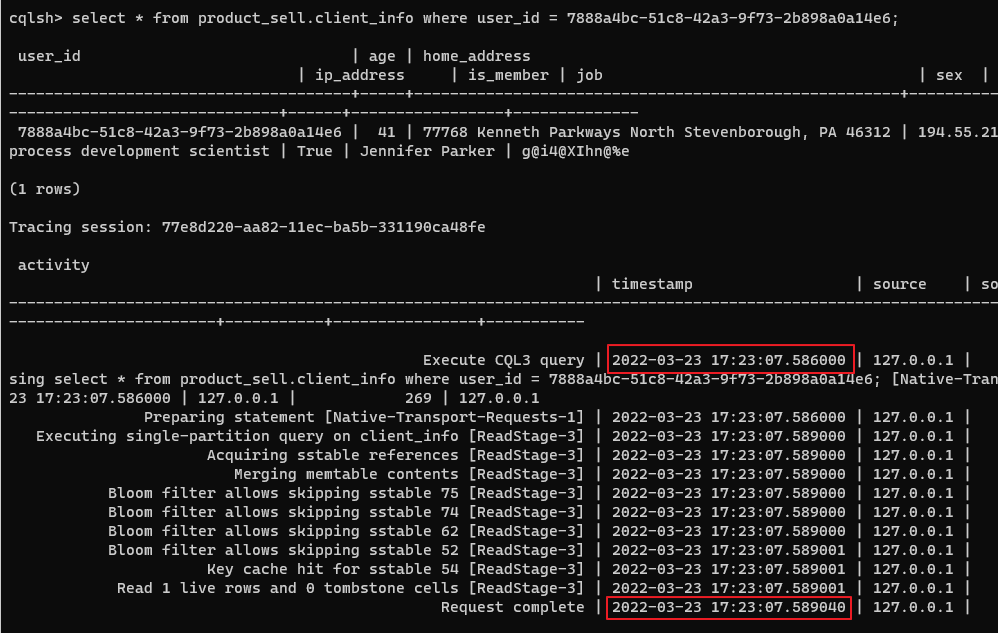 |
1000만 rows를 기준으로 read test시에는 속도가 거의 비슷하게 나왔다.
sqlite3에서는 1~4 ms를 유지하고, Cassandra에서는 3ms를 유지하고 있다.
Read 속도는 큰 차이가 없는 것으로 확인된다.
sqlite에서 index가 없는 경우에는 무려 1.7초나 걸린다.
Query : select * from client_info where user_id = '7888a4bc-51c8-42a3-9f73-2b898a0a14e6'
2. ElasticSerach VS SQLITE3-FTS5 성능 비교
다음은 ElasticSearch와 SQLITE3-FTS5의 성능을 비교해보자.
FTS5(Full-Text-Search)는 SQLITE3에서 제공되는 검색 용도로 사용하는 Virtual Table이다.
단순히 title, content로 이루어진 posts table(혹은 class)를 탐색하는 속도를 비교해보고자 한다.
게시글(posts) Schema
| Column | Column(eng) | type |
|---|---|---|
| 글제목 | title | text |
| 글내용 | content | text |
input 데이터 제작
elasticsearch에 bulk 하기 위해 json 형식의 input 데이터가 필요하다.
이 후, linux 서버에서 아래 쿼리를 날려 bulk 하는 방식으로 데이터를 삽입하고자 한다.
query : curl -XPOST http://localhost:9200/_bulk?pretty -–data-binary @[json_file_name] -H 'Content-Type: application/json'
bulk 데이터 삽입시에는 아래 이미지와 같이 index 정보가 미리 들어가 있어야 하므로 주의가 필요하다. ( _index = database, _type = table 로 생각하면 된다. )

sqlite3용 데이터는 csv를 bulk하면 되므로 별도로 설명하지는 않겠다.
fts5 사용방법은 https://www.sqlitetutorial.net/sqlite-full-text-search/를 참조했다.
Test 방식
elasticserach, sqlite3 모두 python을 통해 test를 진행했다. content 기준 keyword 검색시 matching 되는 항목들의 title을 가져오는 방식으로 테스트를 시도해보았다.
1
2
3
4
5
6
7
8
9
# elasticsearch
resp = es.search(index="posts", size=10000, query={"match" : { "content" : keyword}})
for hit in resp['hits']['hits']:
result.append(hit['_source']['title'])
# sqlite3
for row in cursor.execute(
"SELECT title from posts where content MATCH '" + keyword + "'"):
result.append(row[0])
test 결과

10만개의 record를 대상으로 테스트 진행시 sqlite가 약 10배 정도로 빨랐다.
하지만 Http transport를 하는것과 local에서 가져오는 것의 차이가 있기에 당연히 Elasticsearch가 sqlite 보다는 느릴 수 밖에 없을 것이라 생각한다.
그래도 ElasticSearch도 10만개의 record를 대상으로 약 163ms 만에 게시글을 검색이 가능하다는 점은 매우 흥미로웠다. REST API로 쉽게 사용도 가능하고 저정도면 속도도 나쁘지 않은 것 같아보인다.
match_size는 실제로 검색을 통해 찾은 항목들의 개수인데 두 개 모두 일치하는 것을 알 수 있었다.
글을 마치며
책에서 본 내용을 바탕으로 NoSQL를 접해보고, 성능 비교를 위해 이들을 간단하게나마 사용해 볼 수 있었다.
사실 테스트를 제대로 한건지도 의문이긴 하지만 더 깊게 파고들면 공부할 것이 많아질 것 같아 이정도까지만 해보고 마치려 한다.
확실히 RDBMS 만으로는 만족하지 못하는 요구사항들이 존재하는 것이 있었고, 이것들을 충족시키기 위해 다른 컨셉의 DB가 필요하다는 것을 확실히 알 수 있었다.
물론 이번에 해본 것은 모두 빙산의 일각이겠지만 그래도 재미난 경험이었다.
개인적으로 좀 더 확실한 테스트 환경 구성을 위해 EC2를 사용했어야 하지 않았나 싶지만 이것은 다음 기회에 도전해봐야겠다.
이 글이 비슷한 주제로 궁금증을 가지는 사람들에게 조금이나마 도움이 되었으면 한다.
(o゚v゚)ノ (o゚v゚)ノ
댓글남기기