[DataBase][NoSQL] 분산 KVS, 와이드 컬럼 스토어, 도큐먼트 스토어, 검색엔진에 대해서 알아보자 - 02. 와이드 컬럼 스토어(카산드라)
이번 post에서는 이전글에 이어서 와이드 컬럼 스토어에 대해서 알아보도록 하겠다.
NoSQL - 와이드 컬럼 스토어(Apache Cassandra)
Wide-Column Database 란 무엇일까?
Wide Column data 베이스는 NoSQL의 종류중 하나로 Column의 네이밍이나 포맷이 Row마다 다를 수 있는 DataBase이다. 이 조건은 KVS와 마찬가지로 같은 테이블 안에서도 row별 column이 다르게 정의될 수 있다. Value가 column 기준으로 저장되기 때문에 전체열에 대해서 빠르게 load하고 search 할수 있다고 한다.
RDBMS와는 다르게 record가 column이 고정된 상태로 적재되지 않기 때문에 컬럼 추가가 자유롭다. 물론 Wide-Column DB 또한 row 컨셉을 가지고 있으나 row를 가져올때는 개별 column을 read 하는 것으로 동작한다.
그리고 wide-column DB는 분산 시스템을 적용할 수 있어 가용성이 높다. 컨셉만 놓고 봤을때는 KVS와는 어떤 관계가 있을까라고, 생각해볼 수 있는데 value의 단위가 다르다.
Key-Value store에서는 value 자체가 하나의 object 단위가 되는 것이고 Wide Column DB에서는 Column 별로 Value가 나뉘게 된다. 그래서 Wide Column DB 에서는 필요한 Column만 빠르게 가져올 수 있고 Key-Value DB에서는 일단은 모든 Object를 긁어온 다음에 그 안에서 다시 파싱을 해야하는 구조로 이해된다.
아래 이미지를 참조하면 어떤 차이가 있는지 알 수 있다.
(1) KVS
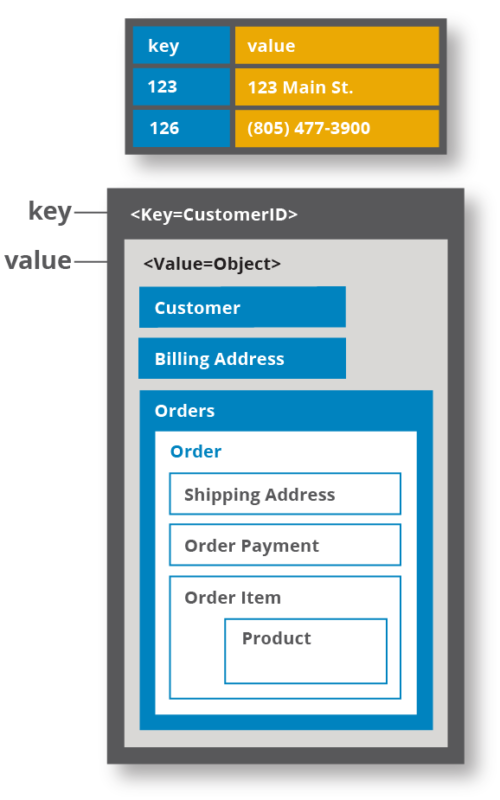
(2) Wide Column DB

Wide-Column Database가 사용되는 Case
넓은 열 데이터베이스는 열이 모든 행에 대해 항상 동일하지 않고, 여러 데이터베이스 노드에 분산될 수 있는 대규모 데이터 셋이 필요할때 사용하는 것이 이상적이라고 한다.
예시로는 다음과 같이 소개가 된다.
- Log data
- IOT sensor data
- Time-series data, such as temperature monitoring or financial trading data
- Attribute-based data, such as user preferences or equipment features
- Real-time analytics
Apache Cassandra
WCS의 대표적인 DB로는 Cassandra가 있다.
설치는 아래와 같이 docker 에서 간단하게 할 수 있으니 참고 바란다.
start cassandra & cql docker
1
2
docker run -p 9042:9042 --name cassandra --hostname cassandra --network cassandra cassandra
docker run --rm -it --network cassandra nuvo/docker-cqlsh cqlsh cassandra --cqlversion="3.4.5" -p 9042
Cassandra - 소개 & 구성요소
Cassandra의 기원은 페이스북(현 메타)에서 시작되었다. 페이스북에서 inbox search 기능을 위해 개발이 되었으며, 2008년 7월에 open source화 되었다. 그 후로 2009년 3월에 Apache 재단에 합병되었다.
Cassandra의 대표적인 특징은 DB가 분산 노드(서버)로 구성이 가능하다는 것이다. 카프카나 k8s 에서도 보았던 replication 개념이 Cassandra에도 존재하며 이로 인해 높은 가용성 유지가 가능하다.
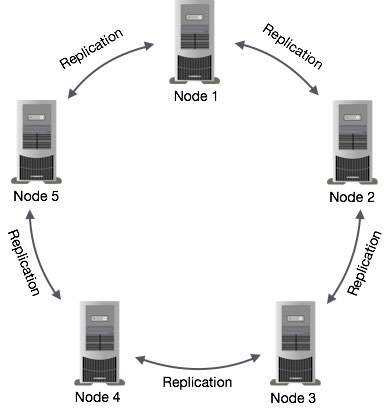
[출처] : https://www.tutorialspoint.com/cassandra/cassandra_architecture.htm
카산드라의 구성요소
| Component | Description |
|---|---|
| Node | It is the place where data is stored. |
| Data center | It is a collection of related nodes. |
| Cluster | A cluster is a component that contains one or more data centers. |
| Commit log | The commit log is a crash-recovery mechanism in Cassandra. Every write operation is written to the commit log. |
| Mem-table | A mem-table is a memory-resident data structure. After commit log, the data will be written to the mem-table. Sometimes, for a single-column family, there will be multiple mem-tables. |
| SSTable | It is a disk file to which the data is flushed from the mem-table when its contents reach a threshold value. |
| Bloom filter | These are nothing but quick, nondeterministic, algorithms for testing whether an element is a member of a set. It is a special kind of cache. Bloom filters are accessed after every query. |
[출처] : https://www.tutorialspoint.com/cassandra/cassandra_architecture.htm
모든 write 연산은 commit log에 저장이 된다. 이후에 데이터틑 mem-table에 저장이 되고, mem-table이 꽉차면 SStable 데이터 파일에 작성된다. 일단 메모리 버퍼를 사용해서 빠르게 연산하고 flush는 실제 Disk에 저장하는 구조인 것으로 파악된다.
read 연산시에는 mem table과 SST table을 뒤져서 필요한 데이터를 가져온다.
Cassandra - Data Model
Cassandra에는 RDB의 Database, Table 대신 KEYSPACE, Column Family 라는 개념이 존재한다.
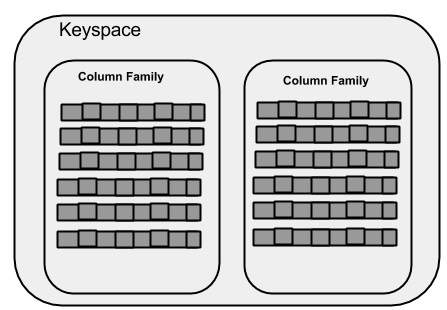
우선 KEYSPACE 부터 살펴보면 가장 외곽에 존재하는 container 이다.
여기서 container는 docker container의 개념이 아님!
RDB에서의 database로 생각을 하면 될 것 같다. 어쨋든 이 컨테이너에서는 Replication factor, Replica placement strategy 등을 설정할 수 있다.
여기서 Replica placement strategy란 어떤 방식으로 복제본을 저장할 것인가에 대한 속성이다. simple, network topology 이렇게 두 가지가 존재한다.
실무에서는 어떤 식으로 구성할 수 있을지에 대해서는 감이 잡히지는 않는데 개념에 대해서만 알아두도록 하자.
replica placement strategy
| strategy | description |
|---|---|
| simple | 하나의 데이터 센터를 가지고 있을 경우 사용하는 방식이라고 한다. 첫번째 카피가 정해진 후 시계 방향으로 replication factor 만큼 복사한다. 다수의 Data Center가 구성된 상태에서는 이를 사용하면 안된다. |
| network topology | 개별적으로 data-center가 구성된 경우 사용하는 전략이다. DataCenter-1에는 replication 3개, DataCenter-2 에는 replication 5개 등과 같은 식으로 구성할 수 있다. |
다음으로 Column-family가 존재한다. RDBMS에서 Table에 해당되는 것인데 차이점이 있다면 column 단위로 값이 저장된다는 점과 row 마다 해당 column의 값이 존재하지 않아도 된다는 것이다.
예를 들면 Row-1 에는 Column 1,2,3 이 존재하지만 Row-2에는 Column 1,4 만 존재한다는 등의 방식이다.
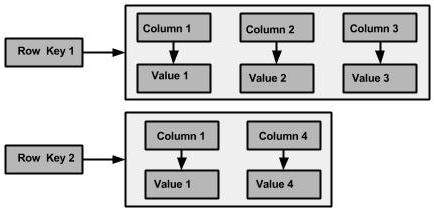
이것이 자칫 row마다 column의 schema가 다르다고 생각할 수 있는데 그냥 null이 들어가는 방식이다. wide column은 그래서 upsert 방식으로 insert 구문이 동작한다. RDB와는 조금 다르다.
아래 쿼리의 동작을 보면 이해가 쉬울 것이다. userid = ‘1237’로 last_update_timestamp를 삽입하고 이후에 insert 구문으로 item_count를 삽입하였으나 업데이트가 됨을 알 수 있다.
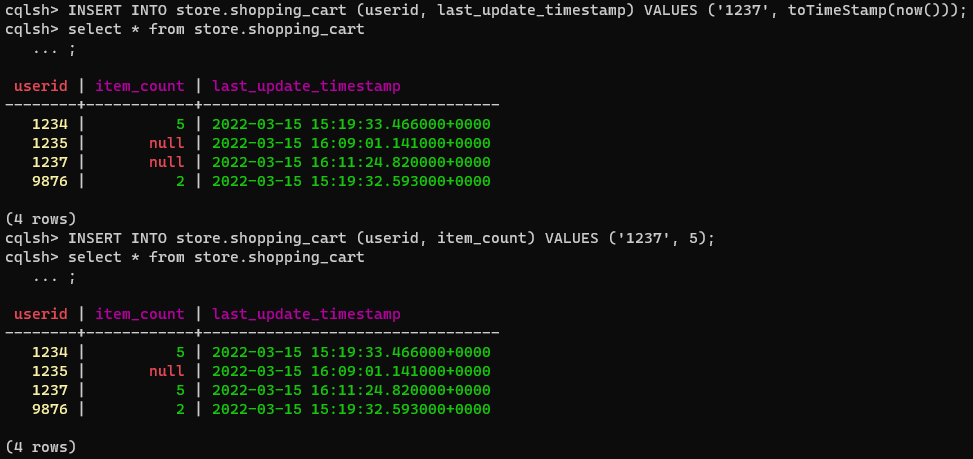
이처럼 cassandra 에서는 column 지향적으로 데이터가 적재되고 있음을 알 수 있다. column 별로 데이터가 적재되기 집계할때 유리한 점이 생기는 것이다.
column에는 기본 자료형( int, blob 등등.. )과 map, list, user define column에 대해 삽입할 수 있다.
다음은 RDB와 Cassnadra의 데이터 모델을 비교한 표이다.
| RDBMS | Cassandra |
|---|---|
| RDBMS deals with structured data. | Cassandra deals with unstructured data. |
| It has a fixed schema. | Cassandra has a flexible schema. |
| In RDBMS, a table is an array of arrays. (ROW x COLUMN) | In Cassandra, a table is a list of “nested key-value pairs”. (ROW x COLUMN key x COLUMN value) |
| Database is the outermost container that contains data corresponding to an application. | Keyspace is the outermost container that contains data corresponding to an application. |
| Tables are the entities of a database. | Tables or column families are the entity of a keyspace. |
| Row is an individual record in RDBMS. | Row is a unit of replication in Cassandra. |
| Column represents the attributes of a relation. | Column is a unit of storage in Cassandra. |
| RDBMS supports the concepts of foreign keys, joins. | Relationships are represented using collections. |
[출처] : https://www.tutorialspoint.com/cassandra/cassandra_data_model.htm
글을 마치며
이처럼 간략하게 Wide-Column Store에 대해서 알아보았다. RDBMS와는 확실히 다른 개념이기 때문에 이해하는 것이 조금 힘들었다. 특히, Family Columns 개념은 영문서로만 문맥을 파악하기에 쉽지 않았다. 열지향 DB다 보니 저렇게 표현을 한 것이라서 이제는 조금 이해가 된다.
확실히 WCS 컨셉은 RDBMS와 비교시, RDB에서는 할 수 없었던 것들을 편리하고 쉽게 사용할 수 있어서 수요가 생길 수 밖에 없는 구조인 것 같다. 페이스북에서는 inbox search(mail search)에서 이것을 사용했다고 하는데 메일 시스템도 자기들이 구현 중인가 보다. 어떻게 사용 중인지는 다음에 기회가 된다면 찾아봐야겠다.
이번 포스트를 통해 WCS에 대한 맛보기를 진행할 수 있었다. 이제 다음은 document store 차례인데 이것은 또 어떻게 저장이 되어있을지 너무 궁금하다. 다음 글에서 찾아 뵙겠습니다.
참조 사이트
- tutorialspoint : https://www.tutorialspoint.com/cassandra/cassandra_data_model.htm
- code-review.com : https://www.code-view.com/2016/12/data-replication-in-cassandra-database.html
- cassandra 홈페이지 : https://cassandra.apache.org/doc/latest/index.html
댓글남기기