[DataBase][NoSQL] 분산 KVS, 와이드 컬럼 스토어, 도큐먼트 스토어, 검색엔진에 대해서 알아보자 - 01. 서론 및 분산 KVS
서두
요즘 변성윤님의 추천으로 “빅데이터를 지탱하는 기술” 보고 있다.
현재 4장까지 2회독을 하고 있는 중인데 4-4에서 NoSQL에 관한 설명이 있는 것을 보았다.
RDBMS만 사용해봤던 나에게는 소개해준 내용들이 뙇! 와닿지는 않았다.
“음.. 분산 KVS? 아! Key-Value Store 방식이구나! 음.. 와이드 컬럼 스토어..? Multi-Key..? 으으ㅡ음…”
각 항목들에 대해서 "어떤 방식으로 동작을 하는지는 이해를 하겠는데.. 그래서 어떤 상황에서 어떻길래 저렇게 많은 종류가 있는거지?" 라는 의문이 들지 않을 수 없었다.
이번 포스트에서는 각 항목들이 어떤 방식으로 동작을 하며, 목적에 따른 데이터셋을 확보한 후에 각각 어떤 성능을 보이고 있는지에 대해서 정리를 해보고자 한다.
플랫폼은 책에서 소개한 아래 항목들로 정했다.
| Category | Platform |
|---|---|
| 분산 KVS | Dynamo DB |
| 와이드 컬럼 스토어 | Apache Cassandra |
| 도큐먼트 스토어 | Mongo DB |
| 검색 엔진 | Elastic Search |
조사전 알아보고자 하는 내용에 대해 정리
조사를 하기 전에 목표하는 것에 대해서 명확하게 정의하고, 이를 위해 어떤것들이 필요할지 알아보고자 한다.
우선 NoSQL은 RDB가 충족해줄 수 없는 부분에 대해서 만족을 시켜주고자 만들어진 DB Engine 이라고 한다.
책에서 소개된바로는 아무래도 빅데이터 관련 책이다보니 “데이터를 기록하고 곧바로 활용하고자 하는 경우 실시간 집계, 검색에 적합“하기 때문에 NoSQL이 사용이 된다고 되어있다.
돌이켜보면 이전 회사에서 사용했던 MS-SQL(RDB) 라든가 책에서도 소개되었고 토이 프로젝트로 사용해봤던 열지향 스토리지(Parquet) 같은 경우에는 데이터를 기록하는데 상당히 시간이 소모되었던 것 같다. SQLITE만해도 “BEGIN, END” 안하고 INSERT 쿼리를 날리면 얼마나 속도가 느렸던가..
그래서 핵심은 얼마나 빠르게 Write를 하고, 얼마나 빠르게 Read 할 수 있는지가 NoSQL을 사용하는 핵심이라고 생각한다.
실시간 서비스를 보장하기 위해서는 ms 단위로 무언가가 수행되어야 가능하지 않을까 싶다.
어쨋든 위와 같은 이유로 NoSQL들의 특징과 장단점을 간략하게 조사해본 후 아래의 항목들에 대해서 Test를 직접 해보고자 한다.
TEST 항목
- 1000만 Record 정도 가지고 있는 정형 데이터(csv) 파일을 SQLITE(RDB), MongoDB(NoSQL)에 Read / Write 했을때 속도 차이 조사.
- RDB와 NoSQL이 얼마만큼의 차이를 가지고 있는지 살펴보자.
- Dynamo DB(분산 KVS), MongoDB(도큐먼트 스토어) 에 비정형 데이터(JSON) 1000만 Record를 Read / Write 했을때 속도 차이 조사.
- 분산 KVS와 도큐먼트 스토어 모두 비정형 데이터를 삽입할 수 있다고 한다.
- 소개된 NoSQL 4개에다가 다양한 종류의 스카마의 1000만 레코드를 Read / Write 했을때 속도 차이 조사.
- 목적에 따라 NoSQL이 store하는 방식이 나눠진 것이라고 생각한다. 각각의 장점이 되는 상황을 고려해서 데이터셋을 수집한 후에 어떤 차이가 있는지 테스트 해보자.
그럼 차례대로 하나씩 알아보도록 하자.
NoSQL - 분산 KVS (Dynamo DB)
“분산 Key-Value Store” 을 알기전 우선 “Key-Value Store”가 무엇인지 살펴보자. Key-Value Store는 흔히 사용하는 Map과 유사한 형태다. Value를 식별하기 위한 Key가 존재하고 그 Key를 통해 Value를 빠르게 찾아낼 수 있는 방식이다.
[ 출처 ] : https://hazelcast.com/glossary/key-value-store/
RDB와 비교했을때 이는 어떤 차이가 있을까? RDB는 Row 기준으로 Record를 차곡차곡 쌓아가는 행지향 방식의 스토리지다. Python의 list나 C++의 Vector 등을 생각해보자. 해당 컨테이너에 record를 쌓고 찾을때 방식을 기억하는가? 순차적으로 찾거나 아니면 Binary Search를 통해 빠르게 찾아내곤 한다. 하지만 그보다 더 빠른 것이 Hash Table을 통해 항상 log(1)로 값을 찾아오는 Map이다.
위의 예시를 다시 행지향 스토리지(RDB)와 Key-Value Store로 빗대어 생각해보자. 과연 Find 하는게 어떤 것이 더 빠를까? 당연히 후자가 되는 것이다.
https://hazelcast.com/glossary/key-value-store 페이지에서 소개되는 KVS 데이터 베이스의 use cases들을 살펴보자.
- 웹 어플리케이션 : user id를 Key값으로 user session 세부 정보와 기본 설정을 저장. 필요할때마다 빠르게 쓰고 읽을 수 있음.
- 실시간 추천 시스템 : 웹 사이트를 빠르게 이동할때 중간중간에 보이는 추천광고를 이를 통해 구현한다고 한다.
그래서 분산 KVS란?
이제 위에서 KVS의 뜻을 알아봤으니 분산 KVS에 대해서도 살펴보자. 경험상 분산이라는 형용사가 나오면 이것은 항상 Multi Computer에 관한 내용이였다. 아니나 다를까 이도 마찬가지다.
Multi Node로 구성된 KVS 시스템을 분산 KVS라고 한다. 분산하면 떠오르는 장점들을 생각해보자. 편리한 Scale-Out, 대용량 처리 등등이 있다. 여러 컴퓨터를 사용해 단일 컴퓨터보다 더 뛰어난 환경의 KVS System을 구축해놓은 것이 장점이라고 볼 수 있다.
KVS의 장점과 분산 시스템으로 빠른 검색 + 대용량 저장이 가능하니 서비스를 운영하는 입장에서는 편리하지 않을수가 없다.
Dynamo DB
DynamoDB는 AWS에서 제공하는 분산형 KVS DB 플랫폼이다. Service introduction을 살펴보면 RDB에 비해 저렴하고 빠른 속도를 제공하고, 총 사이즈가 얼마가 되든간에 Read 하는데 한자릿수 ms의 속도를 보장한다고 한다.
그리고 일부 AWS 플랫폼이 그러하듯 운영적인 쪽은 아예 신경을 쓰지 않아도 된다고 하니 편리할 것 같다. 다음은 DynamoDB의 작동 방식에 대해서 알아보자.
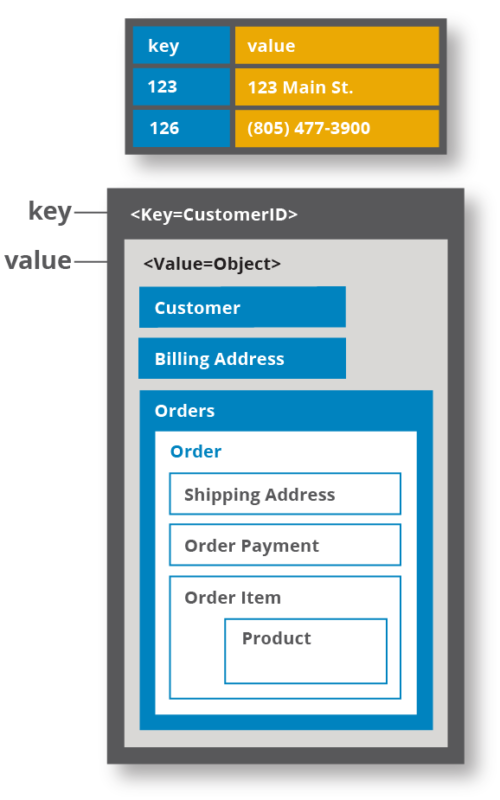
우선 구성에 대해서 살펴보자. 일반적인 DB와 마찬가지로 Table과 Attribute가 있고 Items라는 컨셉이 존재한다. Table은 어느 DB와 마찬가지로 똑같이 DB안에서 구분되는 메인 개체이다. items는 Table안에 들어있는 record라고 생각하면 된다. 그리고 attribute가 있는데 각 item 안에 들어있는 속성이다.
근데 여기서 RDB와는 다른것이 Attribute는 item마다 공통된 Schema를 가지지 않는다는 뜻이다. 아래의 그림을 보면 item(PersonID=101)은 LastName, FirstName, Phone 3개의 Attribute를 가지고 있으나, item(Person=102)은 Address라는 attribute를 가지고 있다. 그리고 이 Address Attribute 내부에서 또다른 Attribute들이 구성되어 있음을 알 수 있다.

다음으로는 Key에 대해서 알아보자. Key-Value Store이므로 당연히 Primary-Key가 필요할 것이다. DynamoDB에서는 두가지 종류의 Primarykey를 지원한다.
첫번째 Primary Key는 Partition Key이다. 하나의 attribute 만이 설정가능하며 중복값은 허용될 수 없다. 위의 그림을 예로들면 PersonID가 파티션 키가 되는데 저 아이디는 Table 내부에서 고유해야하기 때문에 값이 겹치면 안된다.
두번째는 Partition key and sort key 이다. 아래 이미지의 Music Table을 보면 Artist, Songtitle 두가지로 Primary Key가 구성되어 있는 것을 알 수 있다. 이 두가지 Attribute는 Music Table에서는 반드시 구성이 되어야하는 기본 Attribute가 된다. 아래 예제와 같이 현실 세계에서는 하나의 Artist가 여러개의 Song을 가질 수 있지 않은가? 이를 DynamoDB 상에서 표현하고 싶을때 “Parition and sort key”를 사용해보자.
복합키를 사용할 경우 Search 검색어의 조건으로 Artist만 제공될때 Music Table에서 조건에 맞는 Artist를 가지는 item을 모두 검색한다. sort key로 설정된 것에 대해서는 여러개가 검색되지 않는지는 Test를 하면서 살펴봐야 겠다.

[ 출처 ] : https://docs.aws.amazon.com/ko_kr/amazondynamodb/latest/developerguide/images/HowItWorksMusic.png
이 밖에도 DynamoDB는 보조 인덱스 및 DynamoDB Streams라는 구성요소가 있는 것으로 보인다. 이에 대해서는 이 글에서 다룰 내용의 범위를 벗어난 항목인 것 같아서 추후에 기회가 되면 찾아보도록 해야겠다.
여기까지 왔다면 분산 KVS의 컨셉에 대해서는 어느정도 이해가 되었을 것으로 생각되어 소개는 여기까지만 하고 마치도록 하겠다.
다음 글을 시작으로 와이드 컬럼 스토어, 도큐먼트 스토어, 검색엔진 등등에 대해서 정리해보도록 하겠다.
댓글남기기